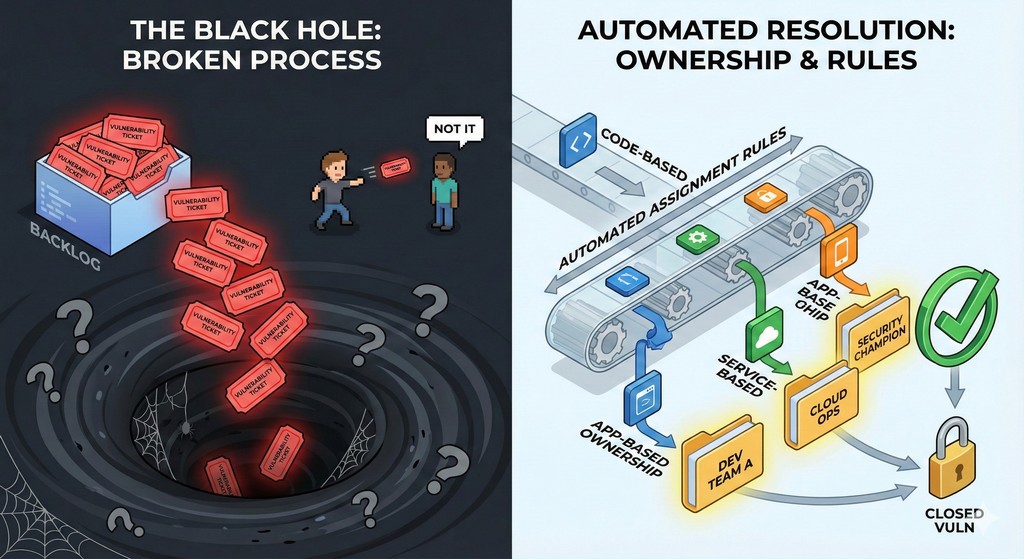
Une nouvelle vulnérabilité a été découverte par votre scanner de sécurité. Un ticket est automatiquement généré dans Jira, se voit attribuer une priorité « Élevée » et est déposé dans un arriéré massif et débordant. Et là, il reste. Et reste. Les jours se transforment en semaines. L’équipe de sécurité envoie un rappel. L’équipe d’ingénierie dit qu’elle s’en occupera. Le ticket est passé d’un développeur à un autre comme une patate chaude, chacun affirmant que ce n’est pas son code ou que ce n’est pas sa responsabilité. Finalement, le ticket devient obsolète, un fantôme oublié dans la machine, tandis que la vulnérabilité reste grande ouverte.
Ce scénario n’est pas un échec de la détection ; c’est un échec du processus. Le meilleur scanner de sécurité au monde est inutile si ses résultats sont ignorés. Le trou noir où les tickets de vulnérabilité vont mourir est l’un des plus grands défis de la sécurité des applications. La cause profonde est rarement un manque de compétence ou de volonté de corriger les problèmes. Au lieu de cela, c’est un système de propriété et d’acheminement défaillant. Pour garantir que les vulnérabilités sont réellement fermées, les organisations doivent aller au-delà de la simple création de tickets et construire des systèmes intelligents de propriété et d’affectation automatisée.
Le piège du ticket « sans propriétaire »
Le parcours d’un ticket de vulnérabilité se termine souvent avant même d’avoir commencé. Lorsqu’un ticket est créé sans propriétaire clair et immédiat, il entre dans un état d’incertitude. Cela se produit pour plusieurs raisons courantes.
Premièrement, de nombreux outils de sécurité ne sont pas intégrés au code de manière significative. Un scanner pourrait signaler une vulnérabilité dans une application de production mais n’avoir aucun contexte sur quelle équipe, ou même quel développeur spécifique, a écrit le code offensant. Le ticket est alors affecté à un arriéré d’« ingénierie » générique ou à un « champion de la sécurité » rotatif qui pourrait ne pas avoir le contexte nécessaire pour corriger le problème efficacement. Cela conduit à un processus de triage fastidieux où quelqu’un doit manuellement enquêter sur le code et retrouver la bonne personne.
Deuxièmement, sans un modèle de propriété prédéfini, les tickets sont souvent victimes de l’effet spectateur. Lorsqu’un ticket est affecté à toute une équipe, l’hypothèse est que quelqu’un d’autre s’en chargera. Aucune personne seule ne se sent responsable. Cela est particulièrement vrai dans les grandes organisations avec des architectures de microservices complexes, où plusieurs équipes pourraient contribuer à une seule application. En conséquence, le ticket languit jusqu’à ce qu’un analyste de sécurité intervienne manuellement, ce qui fait perdre un temps précieux et crée des frictions entre la sécurité et l’ingénierie. Le coût de cette inefficacité est significatif ; des études sur le développement de logiciels montrent que le coût de correction d’un bogue augmente de façon exponentielle plus il est trouvé tard dans le cycle de développement.
Enfin, les processus d’acheminement manuels sont lents et sujets aux erreurs. Un responsable de la sécurité transférant des e-mails ou taguant des personnes dans les commentaires Jira n’est pas une stratégie évolutive. À mesure que le volume des vulnérabilités augmente, cette approche manuelle s’effondre inévitablement, entraînant des tickets manqués et un risque accru.
Définir des modèles de propriété clairs
L’antidote au ticket sans propriétaire est un modèle de propriété clair et cohérent. Ce modèle doit être défini avant que les tickets ne commencent à circuler. Il existe plusieurs approches efficaces :
- Propriété basée sur le code : C’est le modèle le plus direct et le plus efficace. Le propriétaire du code est le propriétaire de la vulnérabilité. En tirant parti des métadonnées de votre système de contrôle de version (comme Git), vous pouvez identifier le développeur ou l’équipe qui a touché en dernier le fichier ou les lignes de code vulnérables. Cela crée une ligne de responsabilité directe. Si vous l’avez écrit, vous en êtes responsable.
- Propriété basée sur le service : Dans une architecture de micro services, il est logique d’attribuer la propriété au niveau du service. Chaque micro service doit avoir une équipe propriétaire désignée. Lorsqu’une vulnérabilité est trouvée dans un service particulier, le ticket est automatiquement acheminé vers l’arriéré de cette équipe. Cela fonctionne bien pour attribuer la responsabilité à la fois du code de l’application et de ses dépendances d’infrastructure sous-jacente
- Propriété basée sur l’application : Pour les applications monolithiques, la propriété peut être attribuée au niveau de l’application. Une équipe spécifique est responsable de la santé et de la sécurité globales de cette application. Bien que moins granulaire que la propriété basée sur le code, elle fournit un point de contact et une responsabilité clairs.
La clé est de choisir un modèle et de l’appliquer de manière cohérente. Cette information ne doit pas se trouver dans une feuille de calcul ; elle doit être intégrée directement à vos outils. L’objectif est que chaque ticket de vulnérabilité ait un propriétaire désigné dès l’instant où il est créé.
Le pouvoir des règles d’affectation automatisées
Une fois que vous avez un modèle de propriété clair, l’étape suivante consiste à automatiser le processus d’affectation. C’est là que les outils modernes d’automatisation de la sécurité deviennent transformateurs. Au lieu de trier et d’acheminer manuellement les tickets, vous pouvez créer un ensemble de règles qui gère ce travail pour vous.
Une plateforme d’automatisation efficace peut s’intégrer à votre scanner de sécurité, à votre système de contrôle de version et à votre outil de gestion de projet (comme Jira ou Azure DevOps). Avec ces intégrations en place, vous pouvez créer des flux de travail puissants de type « si ceci, alors cela ». Par exemple :
SI une vulnérabilité se trouve dans un fichier commité en dernier par developer@example.com, ALORS affecter le ticket directement à ce développeur.
SI une vulnérabilité est trouvée dans le dépôt payment-service, ALORS affecter le ticket à la « Fintech Squad » et publier une notification dans leur canal Slack.
SI une vulnérabilité est une injection SQL de gravité « Critique », ALORS définir la date d’échéance du ticket à 7 jours et taguer le chef d’équipe.
Ce niveau d’automatisation élimine le trou noir. Chaque ticket est livré directement à la personne ou à l’équipe la mieux équipée pour le corriger, avec tout le contexte nécessaire joint. Cela réduit considérablement le temps moyen de résolution (MTTR). En supprimant le goulot d’étranglement du triage manuel, vous libérez à la fois les équipes de sécurité et d’ingénierie pour se concentrer sur ce qu’elles font le mieux : sécuriser et construire des logiciels. Comme le préconisent des cadres tels que DevOps, la réduction de la friction et l’automatisation des transferts sont essentielles pour augmenter la vélocité et la qualité.
De la détection à la remédiation
Trouver des vulnérabilités n’est que la moitié de la bataille. La véritable mesure d’un programme de sécurité réussi est sa capacité à faire corriger ces vulnérabilités. En s’éloignant des processus chaotiques et manuels et en adoptant des modèles de propriété clairs avec des règles d’affectation automatisées, vous pouvez construire un flux de travail de gestion des vulnérabilités qui fonctionne réellement. Ce changement garantit que chaque ticket a un foyer, que chaque développeur a de la clarté et que chaque vulnérabilité a un chemin clair vers la remédiation. Il est temps d’arrêter de laisser les tickets mourir dans l’arriéré et de commencer à construire un système qui les ferme pour de bon.